

Amazon AWS : Qué es Amazon S3
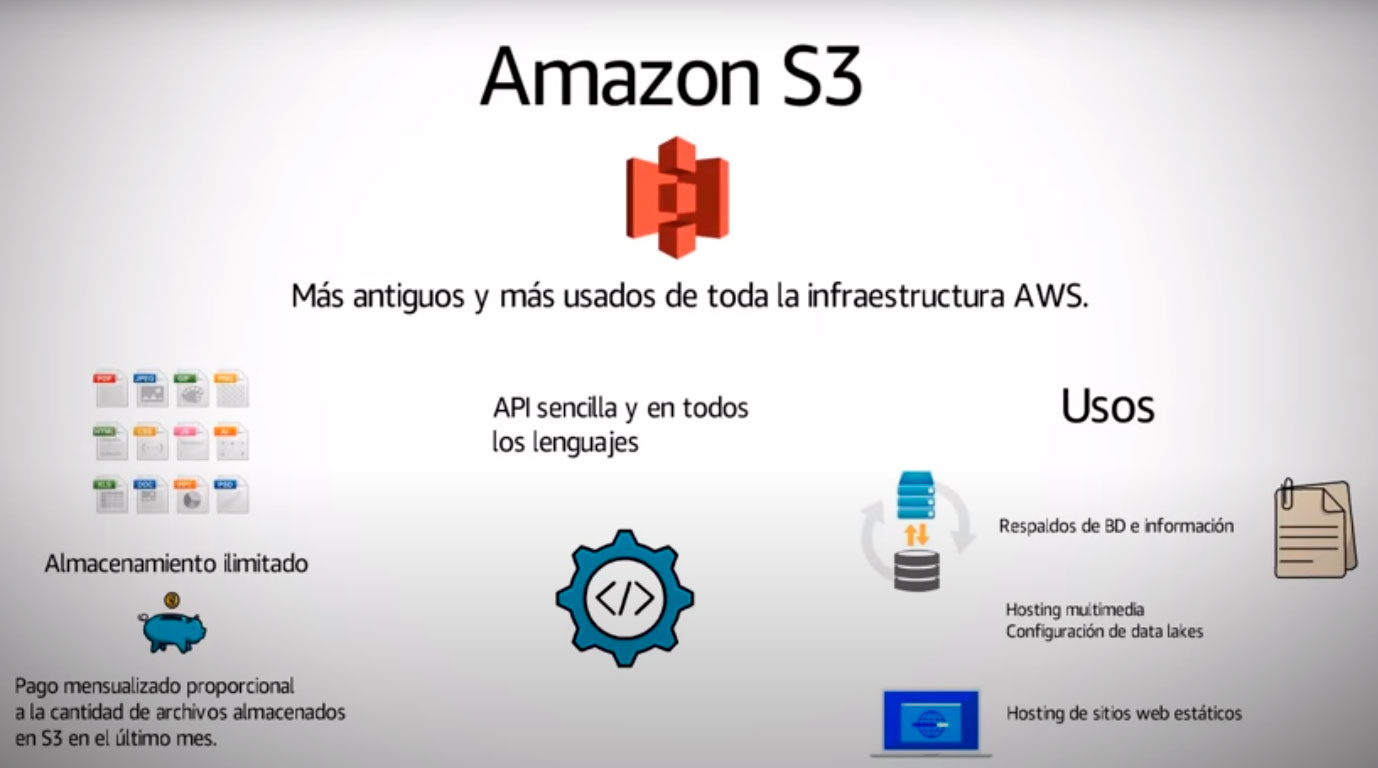
Amazon S3 es uno de los servicios más usados entre la gran cantidad que ofrece AWS además es uno de los servicios más antiguos de la plataforma , S3 es un servicio potente de almacenamiento para cualquier clase de archivos y con capacidad de almacenamiento infinita.
AWS Te cobra únicamente por la cantidad de objetos que tienes almacenados , es decir mientras puedas pagar puedes seguir subiendo cualquier archivo a S3 y pagar mensualmente por mantener estos archivos en la nube.
La simplicidad de S3 viene dada por el hecho de que podemos acceder a la informacion que tenemos en la nube a través de sencillas funciones en su API , con unas cuantas líneas de código ya tendrías toda la potencia de S3 en cualquiera de tus aplicaciones
S3 puede ser usado para almacenar respaldos de bases de datos , respaldos información histórica para tus empresa, puedes usarlo como Hosting multimedia , además puede ser una parte importante de una configuración por ejemplo para data lakes o análisis masivos de datos.
otras caracteristicas poco conocidas de S3 es que nos permite publicar sitios web estáticos , es decir cargamos nuestros archivos html imágenes hojas de estilo y todo lo que necesite nuestro sitio web , y al final S3 nos ofrece una URL de acceso público a nuestro sitio.
Detras de la potencia de S3 esta los Buckets los Buckets son el punto de partida en donde nosotros podemos depositar cualquier tipo de información , cabe mencionar que una de las reglas de Amazon es que los nombres de Los buques deben ser únicos puede existir con el nombre que tú hayas puesto y esto es global a todas las cuentas en Amazon.
Dentro del mismo S3 contamos con distintas categorías de Almacenamiento:
- S3 Estándar: Es la categoría de mayor precio por cada GB almacenado, pero también brinda los precios más bajos por cada solicitud que se haga.
- S3 Infrequent Access: En comparación a S3 estándar, el precio de almacenaje por cada GB disminuye y aumenta el precio de cada solicitud realizada.
- S3 One Zone: Los precios por solicitud realizada son los mismos a S3 IA, pero su precio de almacenamiento disminuye debido a que solamente proporciona una zona de disponibilidad.
- Glacier: Solamente debe ser usado para backups y data histórica, el precio de almacenamiento por GB es el más económico. Está información tendrá una disponibilidad menor, siendo la frecuencia de acceso cada 6 meses o cada año.
→ Usar Amazon S3 con Amazon EC2
Otros Conceptos
Fuente:
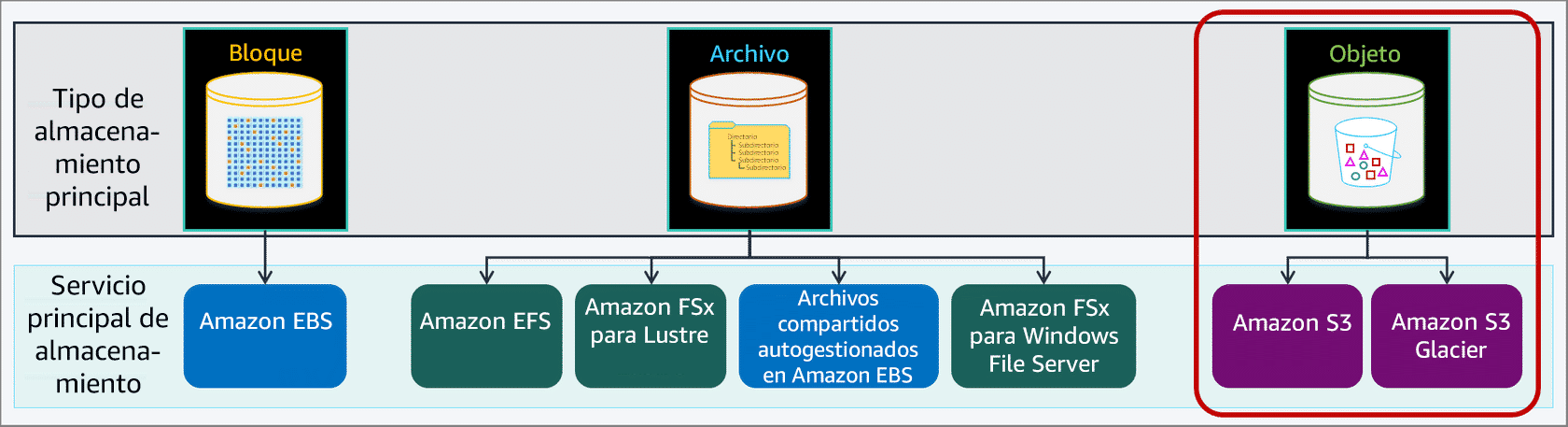
Amazon Simple Storage Service (Amazon S3) es un servicio de almacenamiento de objetos que ofrece una escalabilidad, una disponibilidad de datos, una seguridad y un rendimiento líderes en el sector. Esto significa que clientes de todos los tamaños y segmentos pueden utilizarlo para almacenar y proteger cualquier cantidad de datos para una serie de casos prácticos. Los casos prácticos incluyen los siguientes:
- Lagos de datos
- Sitios web
- Aplicaciones móviles
- Copia de seguridad y restauración
- Archivo
- Aplicaciones empresariales
- Dispositivos de IoT
- Análisis de big data
Amazon S3 ofrece funciones de administración fáciles de usar para que puedas organizar tus datos y configurar controles de acceso ajustados para satisfacer tus requisitos empresariales, organizativos y de conformidad específicos. Amazon S3 está diseñado para una durabilidad del 99,999999999 % (11 9s).
Información general de Amazon S3
Amazon Simple Storage Service (Amazon S3) es el almacenamiento para Internet. Está diseñado para facilitar la computación a escala web o nativa de la nube. Amazon S3 se integra con la más amplia gama de otros servicios de AWS para poder crear cargas de trabajo robustas para la organización.
Amazon S3 cuenta con una sencilla interfaz de servicios web que puedes utilizar para almacenar y recuperar cualquier cantidad de datos desde cualquier lugar de la web. Amazon S3 utiliza API de REST basadas en estándares y diseñadas para funcionar con cualquier conjunto de herramientas de desarrollo de Internet.
Amazon S3 cuenta con varias funciones que puedes utilizar para organizar y administrar tus datos de manera que den soporte a casos prácticos específicos, permitan la eficiencia de los costes, apliquen la seguridad y cumplan con los requisitos de conformidad. Los datos se almacenan como objetos dentro de recursos denominados buckets. Un solo objeto puede tener un tamaño de hasta 5 terabytes. Puedes acceder a los objetos a través de los puntos de acceso de S3 o directamente a través del nombre de host del bucket.
Las funciones de S3 incluyen las siguientes capacidades:
- Añadir etiquetas de metadatos a los objetos.
- Mover y almacenar datos en diferentes clases de almacenamiento de S3.
- Configurar y aplicar controles de acceso a los datos.
- Proteger los datos contra usuarios no autorizados.
- Ejecutar análisis de big data.
- Supervisar los datos a nivel de objeto o bucket.
- Ver las tendencias de uso y actividad del almacenamiento en toda la organización.
Amazon S3 tiene una estructura plana y no jerárquica. Todos los objetos se almacenan en buckets de S3 y pueden organizarse con nombres compartidos llamados prefijos.
Amazon S3 ofrece un rendimiento líder en el sector para el almacenamiento de objetos en la nube. Amazon S3 admite solicitudes paralelas. Esto significa que puedes escalar el rendimiento de S3 por el factor de tu clúster de computación, sin necesidad de personalizar tu aplicación. El rendimiento se escala por prefijo, por lo que puedes utilizar tantos prefijos como necesites en paralelo para lograr el procesamiento requerido. Puedes tener un número prácticamente ilimitado de prefijos. El rendimiento de Amazon S3 admite al menos 3500 solicitudes por segundo para añadir datos y 5500 solicitudes por segundo para recuperar datos. Cada prefijo de S3 puede admitir estas tasas de solicitud, lo que hace que sea sencillo aumentar el rendimiento de manera significativa.
Amazon S3 ofrece una sólida coherencia de lectura tras escritura para las acciones PUT y DELETE en los objetos de tu bucket de Amazon S3 en todas las regiones de AWS. Esto se aplica tanto a las escrituras en objetos nuevos como a las acciones PUT que sobrescriben objetos existentes y a las acciones DELETE. Además, las operaciones de lectura en Amazon S3 Select, las listas de control de acceso de Amazon S3, las etiquetas de los objetos de Amazon S3 y los metadatos de los objetos (por ejemplo, el objeto HEAD) son muy coherentes.
Continúa para obtener más información sobre las funciones de Amazon S3.
Clases de almacenamiento de Amazon S3
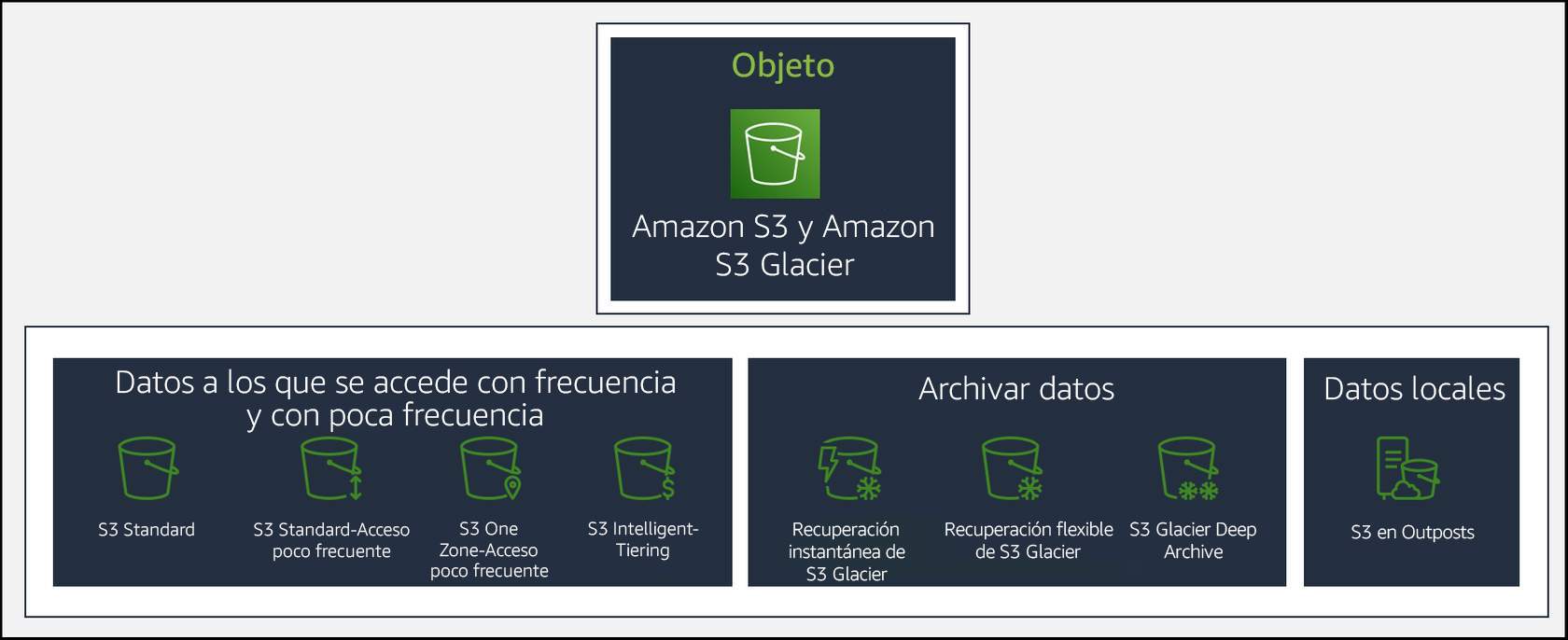
Amazon S3 ofrece una gama de clases de almacenamiento diseñadas para diferentes casos prácticos. Cada clase de almacenamiento de S3 admite un nivel de acceso a los datos específico con los costes o la ubicación geográfica correspondientes. Las clases de almacenamiento de S3 incluyen las siguientes:
- S3 Standard → para el almacenamiento de uso general de datos de acceso frecuente.
- S3 Standard - Infrequent Access → para los datos a los que se accede con menos frecuencia.
- S3 One Zone-Infrequent Access → para los datos a los que se accede con menos frecuencia y los requisitos de disponibilidad más bajos.
- S3 Intelligent-Tiering → para datos con patrones de acceso desconocidos o cambiantes.
- Amazon S3 Glacier Instant Retrieval → para el almacenamiento de archivos de menor coste que pueden requerir su recuperación en cualquier momento.
- Amazon S3 Glacier Flexible Retrieval → para el almacenamiento de archivos de bajo coste con un tiempo de recuperación de minutos a horas.
- Amazon S3 Glacier Deep Archive → para un almacenamiento de bajo coste con tiempos de recuperación de hasta 12 horas.
- Amazon S3 en Outposts → para el almacenamiento de datos híbridos en las instalaciones y el cumplimiento de los requisitos de residencia de datos.
Amazon S3 también ofrece capacidades para administrar los datos a lo largo de su ciclo de vida. Cuando se establece una política de ciclo de vida de S3, los datos se transfieren a una clase de almacenamiento diferente automáticamente sin necesidad de realizar cambios en la aplicación.
Puedes utilizar el análisis de clases de almacenamiento de S3 para supervisar los patrones de acceso a los objetos y descubrir los datos que deben trasladarse a clases de almacenamiento de menor coste. A continuación, puedes utilizar esta información para configurar una política de ciclo de vida de S3 que realice la transferencia de datos.
Las políticas del ciclo de vida de S3 también pueden utilizarse para hacer expirar los objetos al final de su ciclo de vida. Puedes almacenar datos con patrones de acceso cambiantes o desconocidos en S3 Intelligent-Tiering. La política de ciclo de vida mueve los datos automáticamente en función de los patrones de acceso cambiantes entre dos niveles de acceso de baja latencia optimizados para el acceso frecuente y no frecuente. Cuando se accede a subconjuntos de objetos con poca frecuencia durante largos periodos de tiempo, puedes activar dos niveles de acceso de archivo diseñados para el acceso asincrónico y optimizados para el acceso de archivo.
Para obtener información adicional sobre las clases de almacenamiento de Amazon S3, consulta Uso de las clases de almacenamiento de Amazon S3(opens in a new tab) en la Guía del usuario de Amazon Simple Storage Service.
Funciones de Amazon S3
Administración del almacenamiento
Con los nombres de los buckets de S3, los prefijos, las etiquetas de los objetos y el inventario de S3, tienes una serie de formas de categorizar e informar sobre tus datos. Puedes configurar otras funciones de S3 para que actúen. S3 Batch Operations agiliza la administración de tus datos en Amazon S3 a cualquier escala, tanto si almacenas miles de objetos como mil millones.
Con las operaciones por lotes de S3, puedes hacer lo siguiente con una sola solicitud de la API de S3 o con unos pocos pasos en la consola de Amazon S3:
- Copiar objetos entre buckets.
- Sustituir conjuntos de etiquetas de objetos.
- Modificar los controles de acceso.
- Restaurar objetos archivados desde Amazon S3 Glacier.
También puedes utilizar las operaciones por lotes de S3 para ejecutar funciones de AWS Lambda en tus objetos para ejecutar lógica empresarial personalizada, como el procesamiento de datos o la transcodificación de archivos de imagen. Cuando se realiza una solicitud de operaciones por lotes de S3, recibirás una notificación y un informe de finalización de todos los cambios realizados.
Control de versiones
Amazon S3 también admite funciones que ayudan a mantener el control de las versiones de los datos, evitar eliminaciones accidentales y replicar los datos en la misma región de AWS o en otra diferente. Con el control de versiones de S3, puedes conservar, recuperar y restaurar fácilmente cada versión de un objeto almacenado en Amazon S3. Puedes recuperar ante acciones involuntarias de los usuarios y fallos de las aplicaciones.
Para evitar eliminaciones accidentales, habilita la eliminación con autenticación multifactor (MFA) en un bucket de S3. Si intentas eliminar un objeto almacenado en un bucket habilitado para eliminación MFA, requerirás dos formas de autenticación: las credenciales de tu cuenta de AWS y la concatenación de un número de serie válido, un espacio y el código de seis dígitos que se muestra en un dispositivo de autenticación aprobado, como un llavero de hardware o una clave de seguridad Universal 2nd Factor (U2F).
Replicación
Con la replicación de S3, puedes replicar objetos y sus respectivos metadatos y etiquetas de objetos a uno o varios buckets de destino en la misma o en diferentes regiones de AWS. Puedes implementar esta función para reducir la latencia, la conformidad, la seguridad, la recuperación de desastres y otros casos prácticos.
- Puedes configurar Replicación entre regiones (CRR) de S3 para replicar desde un bucket de S3 de origen a uno o más buckets de destino en diferentes regiones de AWS.
- Replicación en la misma región (SRR) de Amazon S3 replica objetos entre buckets en la misma región de AWS. El control de tiempo de replicación de S3 (S3 RTC) ayuda a cumplir los requisitos de cumplimiento de la replicación de datos proporcionando un SLA y visibilidad de los tiempos de replicación.
Retención y conformidad
También puedes aplicar políticas de escribir una vez, leer muchas (WORM) con S3 Object Lock. Esta función de administración de S3 bloquea la eliminación de versiones de objetos durante un período de retención definido por el cliente. La eliminación de la versión del objeto se bloquea para poder aplicar políticas de retención como una capa adicional de protección de datos o para cumplir con las obligaciones de conformidad.
Puedes migrar cargas de trabajo de sistemas WORM existentes a Amazon S3. A continuación, configura el bloqueo de objetos S3 a nivel de objeto y de bucket para evitar la eliminación de versiones de objetos antes de una fecha de retención predefinida o una fecha de retención legal. Los objetos con bloqueo S3 conservan la protección WORM, incluso si se trasladan a diferentes clases de almacenamiento con una política de ciclo de vida de S3. Para hacer un seguimiento de los objetos que tienen bloqueo S3, puedes consultar un informe de inventario de S3 que incluya el estado WORM de los objetos.
Puedes configurar el bloqueo de objetos S3 en uno de los dos modos: modo de gobernanza y modo de conformidad.
- Cuando se despliega en modo de gobernanza, las cuentas de AWS con permisos específicos de IAM pueden eliminar el bloqueo de objetos S3.
- Si necesitas una mayor inmutabilidad para cumplir con la normativa, puedes utilizar el modo de conformidad. En el modo de conformidad, ningún usuario o cuenta raíz puede eliminar la protección.
Supervisión de almacenamiento
Además de las capacidades de administración de Amazon S3, puedes utilizar las funciones de S3 y otros servicios de AWS para supervisar y controlar cómo se utilizan tus recursos de S3. Puedes aplicar etiquetas a los buckets de S3 para asignar los costes a través de múltiples dimensiones empresariales (como centros de costes, nombres de aplicaciones o propietarios). A continuación, puedes utilizar los informes de asignación de costes de AWS para ver el uso y los costes añadidos por las etiquetas de los buckets.
También puedes utilizar Amazon CloudWatch para realizar un seguimiento del estado operativo de tus recursos de AWS y configurar alertas de facturación que se te envían cuando los cargos estimados alcanzan un umbral definido por el usuario.
AWS CloudTrail es otro servicio de supervisión que rastrea e informa sobre las actividades a nivel de bucket y de objeto.
Puedes configurar las notificaciones de eventos de S3 para activar flujos de trabajo, alertas e invocar AWS Lambda cuando se realice un cambio específico en los recursos de S3. Puedes utilizar las notificaciones de eventos de S3 para las siguientes operaciones:
- Transcodificar automáticamente los archivos multimedia a medida que se suben a Amazon S3.
- Procesar los archivos de datos a medida que están disponibles.
- Sincronizar objetos con otros almacenes de datos.
Análisis e información sobre el almacenamiento de Amazon S3
S3 Storage Lens
S3 Storage Lens ofrece visibilidad en toda la organización sobre el uso del almacenamiento de objetos y las tendencias de actividad. Las métricas de uso describen el tamaño, la cantidad y las características del almacenamiento. S3 Storage Lens proporciona recomendaciones automatizadas para ayudar a optimizar el almacenamiento.
Como solución de análisis de almacenamiento, S3 Storage Lens incluye opciones de desglose para generar información a nivel de organización, cuenta, región, bucket o incluso prefijo.
Análisis de la clase de almacenamiento de S3
El análisis de clases de almacenamiento de Amazon S3 analiza los patrones de acceso al almacenamiento para ayudarte a determinar cuándo debes realizar la transición del almacenamiento al que se accede con menos frecuencia a una clase de almacenamiento de menor coste.
Puedes utilizar los resultados para ayudar a mejorar tus políticas del ciclo de vida de S3. Puedes configurar el análisis de la clase de almacenamiento para analizar todos los objetos de un bucket. Como alternativa, puedes configurar filtros para agrupar objetos para su análisis por un prefijo común, por etiquetas de objetos o por ambos, prefijo y etiquetas.
Administración de acceso y seguridad de Amazon S3
Amazon S3 ofrece funciones de seguridad flexibles para bloquear el acceso de usuarios no autorizados a tus datos.
Administración de acceso
Para proteger tus datos en Amazon S3, de forma predeterminada, los usuarios solo tienen acceso a los recursos de S3 que crean. Cada usuario es el propietario de los recursos que crea. Los administradores pueden conceder acceso a otros usuarios utilizando una sola o una combinación de las siguientes funciones de administración de acceso:
- AWS Identity and Access Management (IAM) para crear usuarios y administrar sus respectivos permisos de acceso.
- Listas de control de acceso (ACL) para que los objetos individuales sean accesibles a los usuarios autorizados.
- Políticas de buckets para configurar los permisos de todos los objetos dentro de un solo bucket de S3.
- Puntos de acceso de S3 para simplificar la administración del acceso a los conjuntos de datos compartidos mediante la creación de puntos de acceso con nombres y permisos específicos para cada aplicación o conjunto de aplicaciones.
- Autenticación mediante cadena de consulta para conceder acceso por tiempo limitado a otras personas con URL temporales.
Amazon S3 también admite registros de auditoría que enumeran las solicitudes realizadas a tus recursos de S3 para obtener una visibilidad completa de quién accede a qué datos.
Conectividad local
Puedes utilizar los puntos de enlace de VPC para conectarte a los recursos de S3 desde tu Amazon Virtual Private Cloud (Amazon VPC) y desde tu entorno local. Amazon S3 admite tanto el cifrado en el lado del servidor con tres opciones de administración de claves como el cifrado en el lado del cliente para las cargas de datos.
AWS PrivateLink para S3 proporciona conectividad privada entre Amazon S3 y el entorno local. Puedes aprovisionar puntos de enlace de VPC de interfaz para S3 en tu VPC para conectar tus aplicaciones locales directamente con S3 a través de AWS Direct Connect o VPN de AWS.
Las solicitudes a los puntos de enlace de la VPC de interfaz para S3 se enrutan automáticamente a S3 a través de la red de AWS. Puedes establecer grupos de seguridad y configurar políticas de puntos de enlace de VPC para tus puntos de enlace de VPC de interfaz para obtener controles de acceso adicionales.
Cifrado
Puedes configurar el comportamiento de cifrado predeterminado para un bucket de S3 de modo que todos los objetos nuevos se cifren cuando se almacenen en el bucket. Los objetos se cifran utilizando el cifrado del lado del servidor con las claves administradas de Amazon S3 (SSE-S3) o las claves de AWS Key Management Service (AWS KMS) almacenadas en AWS KMS (SSE-KMS).
Cuando configures tu bucket para utilizar el cifrado predeterminado con SSE-KMS, también puedes habilitar claves de bucket de S3 para disminuir el tráfico de solicitudes desde Amazon S3 a AWS KMS. Al hacer esto, puedes reducir el coste del cifrado.
Cuando se utiliza el cifrado del lado del servidor, Amazon S3 cifra un objeto antes de guardarlo en el disco y descifra el objeto cuando lo descarga.
Block Public Access de S3
Block Public Access de S3 es un conjunto de controles de seguridad que garantiza que los buckets y objetos de S3 no tengan acceso público. Desde la consola de Amazon S3, puedes aplicar la configuración de S3 Block Public Access a todos los buckets de tu cuenta de AWS o a buckets de S3 específicos.
Después de aplicar la configuración a una cuenta de AWS, todos los buckets y objetos existentes o nuevos asociados a dicha cuenta heredan la configuración que impide el acceso público. La configuración de Block Public Access de S3 anula otros permisos de acceso de S3. Al establecer esta configuración, el administrador de la cuenta puede aplicar una política de “no acceso público” independientemente de cómo se añada un objeto, cómo se cree un bucket o si existen permisos de acceso.
Los controles de S3 Block Public Access son auditables y proporcionan una capa más de control. Block Public Access de S3 utiliza las comprobaciones de permisos de buckets de AWS Trusted Advisor, los registros de AWS CloudTrail y las alarmas de Amazon CloudWatch. Habilita Block Public Access para todas las cuentas y los buckets que no desees que sean de acceso público.
Al utilizar puntos de acceso a S3 restringidos a una VPC, puedes proteger tus datos de S3 dentro de tu red privada. Además, puedes utilizar las políticas de control de servicios de AWS para exigir que cualquier punto de acceso a S3 nuevo en tu organización esté restringido al acceso exclusivo a la VPC.
Access Analyzer para S3
Access Analyzer para S3 es una función que supervisa las políticas de acceso a los buckets, garantizando que las políticas proporcionen únicamente el acceso previsto a los recursos de S3. Access Analyzer para S3 evalúa las políticas de acceso a los buckets para que puedas descubrir y corregir rápidamente los buckets con acceso potencialmente no deseado.
Al revisar los resultados que muestran un acceso potencialmente compartido a un bucket, puedes bloquear todo el acceso público al bucket desde la consola de S3. Para fines de auditoría, puedes descargar los resultados de Access Analyzer para S3 como un informe CSV.
IAM proporciona la marca temporal cuando un usuario o rol utilizó por última vez S3 y las acciones asociadas. Utiliza esta información de “último acceso” para analizar el acceso a S3, identificar los permisos no utilizados y eliminarlos con seguridad.
Amazon Macie
Puedes utilizar Amazon Macie para descubrir y proteger los datos confidenciales almacenados en Amazon S3. Macie recopila un inventario completo de S3 de forma automática y evalúa continuamente cada bucket para alertar sobre cualquiera de los siguientes aspectos:
- Cualquier bucket de acceso público
- Buckets no cifrados
- Buckets compartidos o replicados con cuentas de AWS fuera de tu organización
Macie aplica técnicas de machine learning y concordancia de patrones a los buckets que selecciones para identificar y alertarte sobre los datos sensibles, como la información personal identificable (PII). A medida que se generan hallazgos de seguridad, se envían a Amazon EventBridge. Utilizando Macie, puedes integrarte con los sistemas de flujo de trabajo existentes y desencadenar una corrección automatizada con servicios, como AWS Step Functions, para tomar medidas como el cierre de un bucket público o la adición de etiquetas de recursos.
Procesamiento y consulta de datos en Amazon S3
S3 Object Lambda
S3 Object Lambda utiliza las funciones de AWS Lambda para procesar automáticamente la salida de una solicitud GET estándar de S3. AWS Lambda es un servicio de computación sin servidor que ejecuta código definido por el cliente sin necesidad de administrar los recursos de computación subyacentes.
Utiliza la consola de administración de AWS para configurar una función Lambda y asociarla a un punto de acceso de S3 Object Lambda. Amazon S3 llamará automáticamente a tu función Lambda para procesar cualquier dato recuperado a través del punto de acceso de S3 Object Lambda, devolviendo a la aplicación un resultado transformado. Puedes crear y ejecutar tus propias funciones Lambda personalizadas, adaptando la transformación de datos de S3 Object Lambda a tu caso práctico específico.
Consulta in situ
Amazon S3 cuenta con una función integrada y servicios complementarios que consultan los datos sin necesidad de copiarlos y cargarlos en una plataforma de análisis o almacén de datos independiente. Esto significa que puedes ejecutar un análisis de big data directamente en los datos almacenados en Amazon S3.
S3 Select es una función de S3 diseñada para aumentar el rendimiento de las consultas hasta en un 400 % y reducir los costes de consulta hasta en un 80 %. Funciona recuperando un subconjunto de datos de un objeto en lugar de todo el objeto, que puede tener un tamaño de hasta 5 terabytes, y usa expresiones SQL simples para recuperar los datos.
Amazon S3 también es compatible con los servicios de análisis de AWS, como Amazon Athena y Amazon Redshift Spectrum.
- Amazon Athena consulta tus datos en Amazon S3 sin necesidad de extraerlos y cargarlos en un servicio o plataforma independiente. Utiliza expresiones SQL estándar para analizar tus datos, ofrece resultados en cuestión de segundos y se suele utilizar para el descubrimiento de datos no planificados.
- Amazon Redshift Spectrum también ejecuta consultas SQL directamente en los datos en reposo en Amazon S3. Este servicio es más apropiado para consultas complejas y conjuntos de datos grandes (hasta exabytes). Dado que Amazon Athena y Amazon Redshift comparten un catálogo de datos y formatos de datos comunes, puedes utilizar ambos con los mismos conjuntos de datos en Amazon S3.
Casos prácticos de Amazon S3
Los casos prácticos de Amazon S3 son similares a los de muchos sistemas de almacenamiento de archivos. Con un almacenamiento prácticamente ilimitado y de bajo coste, Amazon S3 es una solución de almacenamiento sólida para los requisitos de almacenamiento de datos intensivos y a largo plazo.
Copia de seguridad y recuperación
Crea soluciones de copia de seguridad y restauración escalables, duraderas y seguras con Amazon S3 y otros servicios de AWS. Estos servicios incluyen Amazon S3 Glacier, Amazon Elastic File System (Amazon EFS) y Amazon Elastic Block Store (Amazon EBS). Esta solución aumenta o sustituye las capacidades locales existentes.
AWS y AWS Partners pueden ayudarte a cumplir los objetivos de tiempo de recuperación (RTO), los objetivos de punto de recuperación (RPO) y los requisitos de conformidad. Con AWS, puedes realizar copias de seguridad de los datos que ya están en la nube de AWS o utilizar AWS Storage Gateway para enviar a AWS copias de seguridad de los datos locales.
Recuperación de desastre
Protege los datos críticos, las aplicaciones y los sistemas de las TI que se ejecutan en la nube de AWS o en tu entorno local sin incurrir en el gasto de un segundo sitio físico.
Puedes utilizar los siguientes recursos y servicios de AWS para crear arquitecturas de recuperación de desastres para recuperarte de las interrupciones causadas por desastres naturales, fallos del sistema y errores humanos:
- Almacenamiento de Amazon S3
- Replicación entre regiones de S3
- Servicios de computación, redes y bases de datos de AWS
Archivo
Retira la infraestructura física y archiva los datos con S3 Glacier y S3 Glacier Deep Archive. Estas clases de almacenamiento de S3 conservan los objetos a largo plazo con las tarifas más bajas.
Crea una política de ciclo de vida de S3 para archivar objetos a lo largo de su ciclo de vida o carga los objetos directamente en las clases de almacenamiento de archivo.
Con S3 Object Lock, puedes aplicar fechas de retención a los objetos para protegerlos contra eliminación y cumplir con los requisitos de conformidad.
A diferencia de las bibliotecas de cintas, S3 Glacier te permite restaurar objetos archivados en tan solo un minuto para las recuperaciones aceleradas y de 3 a 5 horas para las recuperaciones estándar. Las restauraciones masivas de datos desde S3 Glacier y todas las restauraciones desde S3 Glacier Deep Archive se completan en 12 horas.
Lagos de datos y análisis de big data
Acelera la innovación creando un lago de datos en Amazon S3 y extrae información valiosa mediante herramientas de consulta in situ, análisis y machine learning. A medida que tu lago de datos crezca, utiliza los puntos de acceso de S3 para configurar el acceso a tus datos, con permisos específicos para cada aplicación o conjunto de aplicaciones.
También puedes utilizar AWS Lake Formation para crear rápidamente un lago de datos y definir y aplicar de forma centralizada políticas de seguridad, gobernanza y auditoría. El servicio recopila datos en tus bases de datos y recursos de S3. A continuación, traslada los datos a un nuevo lago de datos en Amazon S3 y los limpia y clasifica mediante algoritmos de machine learning.
Todos los recursos de AWS pueden escalarse verticalmente para acomodar tus almacenes de datos en expansión, sin inversiones iniciales.
Almacenamiento híbrido en la nube
Configura la conectividad privada entre Amazon S3 y un entorno en las instalaciones con AWS PrivateLink. Puedes aprovisionar puntos de enlace privados en una VPC para permitir el acceso directo a S3 en las instalaciones utilizando IP privadas de tu VPC.
AWS Storage Gateway te permite conectar y ampliar sin problemas tus aplicaciones en las instalaciones al almacenamiento de AWS, a la vez que almacena en caché los datos localmente para obtener un acceso de baja latencia.
También puedes automatizar las transferencias de datos entre el almacenamiento en las instalaciones, incluso desde S3 en Outposts, y Amazon S3 utilizando AWS DataSync. DataSync puede transferir datos a velocidades hasta 10 veces más rápidas que las herramientas de código abierto.
También puedes transferir archivos directamente hacia y desde Amazon S3 con AWS Transfer Family. Este servicio está completamente administrado y permite el intercambio seguro de archivos con terceros mediante SFTP, FTPS y FTP.
Otra forma de habilitar un entorno de almacenamiento en la nube híbrida es trabajar con un proveedor de puerta de enlace de la AWS Partner Network (APN).
Aplicaciones nativas de la nube
Crea aplicaciones móviles y basadas en Internet rápidas y rentables utilizando los servicios de AWS y Amazon S3 para almacenar datos de desarrollo y producción. Estos datos los comparten los microservicios que componen las aplicaciones nativas de la nube.
Con Amazon S3, puedes cargar cualquier cantidad de datos y acceder a ellos en cualquier lugar para desplegar aplicaciones más rápidamente y llegar a más usuarios. Almacenar datos en Amazon S3 significa que tienes acceso a las últimas herramientas para desarrolladores de AWS, la API de S3 y servicios. Puedes utilizar estos recursos para el machine learning y el análisis, lo que te ayudará a innovar y optimizar tus aplicaciones nativas en la nube.
Precios
Con Amazon S3, solo se paga por lo que se utiliza. No se aplica ninguna cuota mínima. Amazon S3 tiene seis componentes de coste que debes considerar al almacenar y administrar tus datos:
- Precios de almacenamiento.
- Precios de solicitud y recuperación de datos.
- Precios de transferencia de datos y de aceleración de la transferencia.
- Precios de administración y análisis de datos.
- Precio para procesar tus datos con S3 Object Lambda.
- Los precios de Amazon S3 varían en función de la región de AWS en la que residas.
Para obtener información adicional sobre los precios de Amazon S3, consulta la página Precios de Amazon S3(opens in a new tab) en el sitio web de AWS.