

Screaming Frog SEO Spider
El Screaming Frog SEO Spider es un rastreador web que le ayuda a mejorar el sitio de SEO, mediante la extracción de datos y auditoría para los problemas comunes de SEO.
El Screaming Frog SEO Spider es una herramienta de auditoría del sitio SEO rápido y avanzado. Se puede usar para rastrear sitios web tanto pequeños como muy grandes, donde la verificación manual de cada página sería extremadamente laboriosa y donde fácilmente puede pasar por alto un redireccionamiento, una meta actualización o un problema de página duplicada. Puede ver, analizar y filtrar los datos de rastreo a medida que se recopilan y actualizan continuamente en la interfaz de usuario del programa.
→ Ir a la Página oficial de Screaming Frog SEO Spider
Qué son las urls canónicas
Las URLs canónicas aparecieron por primera vez en Febrero del 2009. Este método, también conocido como enlace canónico o canonical tag, se utiliza en el mundo del SEO para evitar el contenido duplicado. El “rel=canonical” se sitúa en el header de una página HTML y, aunque no es visible para el usuario, sí lo es para los motores de búsqueda.
El uso de estos enlaces canónicos es muy sencillo. Solo hay que incluir unas pequeña línea en la sección del header y listo.
URL: http://www.dominio.es/producto?session_id=xyz
URL canónica: <link rel=”canonical” href=”http://www.dominio.es/producto” />
Con la URL enlazada se explica al motor de búsqueda que la página del producto es la dirección “original” y la URL con “session id”, una copia. Aunque el uso de enlaces canónicos no es una norma obligatoria de Google, por lo general los motores de búsqueda lo tienen en cuenta a la hora de posicionar las páginas web. La dirección URL con el identificador de sesión ya no se tiene en cuenta, y se remite el link juice a la URL canónica.
Cada URL debe tener un enlace canónico
Por razones preventivas se recomienda asignar a toda URL un canonical tag. Si no hay copia, vincula cualquier URL a sí misma. Se trata de una pequeña protección contra los “scrapers” que copian contenido de los sitios web antes de que se indexe la página y lo publican en otros dominios. El enlace canónico – es decir, el contenido – se entiende como el original. Por supuesto, este consejo sólo se aplica a las páginas originales reales. En las páginas de parámetros, etc. no debe ser enlazada a sí misma, sino a la original. De lo contrario, el efecto se desvanece.
Referencia Qué son las urls canónicas y cómo utilizarlas
Crear Sitemap con Screaming Frog SEO Spider
→ Ir a la Página oficial de Crear Sitemap con Screaming Frog SEO Spider
Para crear un Sitemap con Screaming vamos a configurarlo:
Menu → Configuration → robots.txt → Robots Setting → Escoger Respect robots.txt y dejar marcado Show Internal URLs Blocked by robots.txt y Show External URLs Blocked by robots.txt
Menu → Configuration → robots.txt → Custom → Presionar el boton Add y agrega la url de tu dominio (por defecto se cargara la url del proyecto) y se cargara el robots.txt que has subido a tu servidor.
Menu → Sitemaps → XML Sitemap →
- NoIndex Pages
- Canonicalised → Marcarlo sino lo marcamos nos crea un Sitemap sin Urls.
- Pagineted Urls
- PDFs
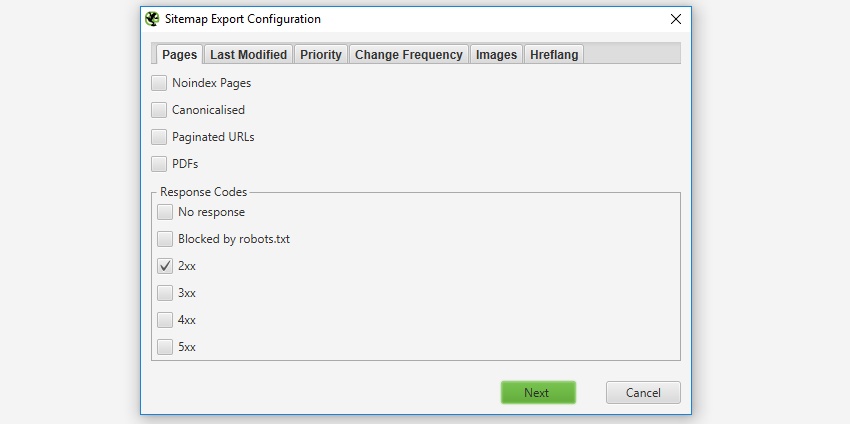
Excluir páginas del mapa del sitio XML
Si ha rastreado URL que no desea que se incluyan en la exportación del mapa del sitio XML, simplemente resáltelas en la interfaz de usuario, haga clic con el botón derecho y "eliminar" antes de crear el mapa del sitio XML. Alternativamente, puede exportar la pestaña 'interna' a Excel, filtrar y eliminar cualquier URL que no sea necesaria y volver a cargar el archivo en modo de lista antes de exportar el mapa del sitio. Alternativamente, simplemente bloquéelos mediante la función de exclusión o robots.txt antes de un rastreo.
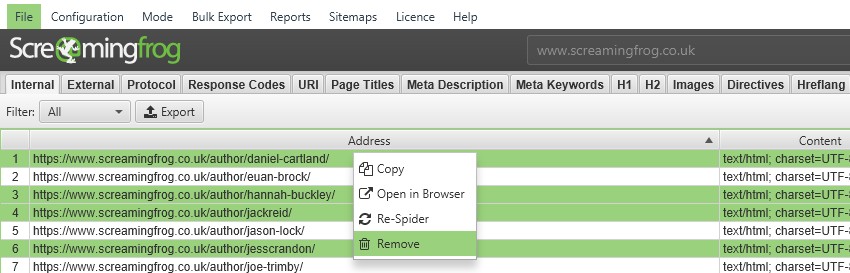
Inserte una entrada de mapa del sitio en su archivo Robots.txt
→ Vea tambien Robots.txt: ¿Qué es, para qué sirve y cómo crearlo?
Finalmente, recomendamos incluir la siguiente entrada de línea en cualquier lugar dentro de su archivo robots.txt, para informar a los motores de búsqueda de la existencia de los Sitemaps XML (independientemente de que ya los haya enviado a las Herramientas para webmasters de Google):
Mapa del sitio: http://www.example.com/sitemap.xml
NOTA: La directiva que contiene la ubicación del sitemap XML se puede colocar en cualquier parte del robots.txt Es independiente de la línea de agente de usuario, por lo que no importa dónde se coloque.
Sitemap: https://www.unidadvirtual.com/sitemap.xml
User-Agent: *
Disallow: /pruebas/
Disallow: /puertasycreaciones/
Disallow: /webadmin/Envíe su mapa del sitio XML a Google
El mapa del sitio XML ya está listo para enviarse a los motores de búsqueda. Recomendamos encarecidamente enviar el mapa del sitio XML a Google a través de las Herramientas para webmasters como una forma de realizar un seguimiento de la indexación.